对象引用、可变性和垃圾回收
变量不是盒子
Python 变量类似于 Java 中的引用式变量,因此最好把它们理解为附加在对象上的标注。
下面的例子说明了在 Python 中为什么不能使用盒子比喻,而便利贴则指出了变量的正确工作方式。
示例 8-1 变量
a和b引用同一个列表,而不是那个列表的副本
>>> a = [1, 2, 3]
>>> b = a
>>> a.append(4)
>>> b
[1, 2, 3, 4]
如果把变量想象为盒子,那么无法解释 Python 中的赋值;应该把变量视作便利贴,这样示例 8-1 中的行为就好解释了
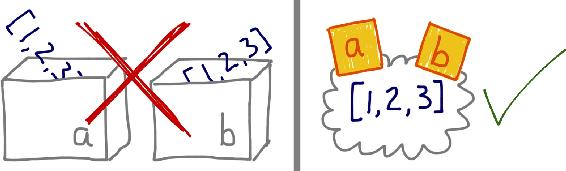
对引用式变量来说,说把变量分配给对象更合理,反过来说就有问题。毕竟,对象在赋值之前就创建了
因为变量只不过是标注,所以无法阻止为对象贴上多个标注。贴的多个标注,就是别名
标识、相等性和别名
charles和lewis指代同一个对象
>>> charles = {'name': 'Charles L. Dodgson', 'born': 1832}
>>> lewis = charles
>>> lewis is charles
True
>>> id(charles), id(lewis)
(4300473992, 4300473992)
>>> lewis['balance'] = 950
>>> charles
{'name': 'Charles L. Dodgson', 'balance': 950, 'born': 1832}
示例 8-4
alex与charles比较的结果是相等,但alex不是charles
>>> alex = {'name': 'Charles L. Dodgson', 'born': 1832, 'balance': 950}
>>> alex == charles
True
>>> alex is not charles
True
示例 8-3 体现了别名。在那段代码中,lewis 和 charles 是别名,即两个变量绑定同一个对象。而 alex 不是 charles 的别名,因为二者绑定的是不同的对象。alex 和 charles 绑定的对象具有相同的值(== 比较的就是值),但是它们的标识不同。
每个变量都有标识、类型和值。对象一旦创建,它的标识绝不会变;你可以把标识理解为对象在内存中的地址。is 运算符比较两个对象的标识;id() 函数返回对象标识的整数表示。
对象 ID 的真正意义在不同的实现中有所不同。在 CPython 中,id() 返回对象的内存地址,但是在其他 Python 解释器中可能是别的值。关键是,ID 一定是唯一的数值标注,而且在对象的生命周期中绝不会变。
其实,编程中很少使用 id() 函数。标识最常使用 is 运算符检查,而不是直接比较 ID
在 == 和 is 之间选择
**== 运算符比较两个对象的值(对象中保存的数据),而 is 比较对象的标识。**
通常,我们关注的是值,而不是标识,因此 Python 代码中 == 出现的频率比 is 高。
然而,在变量和单例值之间比较时,应该使用 is。目前,最常使用 is 检查变量绑定的值是不是 None。下面是推荐的写法:
x is None
否定的正确写法是:
x is not None
is 运算符比 == 速度快,因为它不能重载,所以 Python 不用寻找并调用特殊方法,而是直接比较两个整数 ID。
而 a == b 是语法糖,等同于 a.__eq__(b)。继承自 object 的 __eq__ 方法比较两个对象的 ID,结果与 is 一样。但是多数内置类型使用更有意义的方式覆盖了 __eq__ 方法,会考虑对象属性的值。相等性测试可能涉及大量处理工作,例如,比较大型集合或嵌套层级深的结构时。
元组的相对不可变性
元组与多数 Python 集合(列表、字典、集,等等)一样,保存的是对象的引用。如果引用的元素是可变的,即便元组本身不�可变,元素依然可变。
而 str、bytes 和 array.array 等单一类型序列是扁平的,它们保存的不是引用,而是在连续的内存中保存数据本身(字符、字节和数字)
也就是说,元组的不可变性其实是指 tuple 数据结构的物理内容(即保存的引用)不可变,与引用的对象无关。
默认做浅复制
复制列表(或多数内置的可变集合)最简单的方式是使用内置的类型构造方法。例如:
>>> l1 = [3, [55, 44], (7, 8, 9)]
>>> l2 = list(l1) # list(l1) 创建 l1 的副本
# 对列表和其他可变序列来说,还能使用简洁的 l2 = l1[:] 语句创建副本
>>> l2
[3, [55, 44], (7, 8, 9)]
>>> l2 == l1
True
>>> l2 is l1
False
l1 和 l2 指代不同的列表,但是二者引用同一个列表 [66, 55, 44] 和元组 (7, 8, 9)
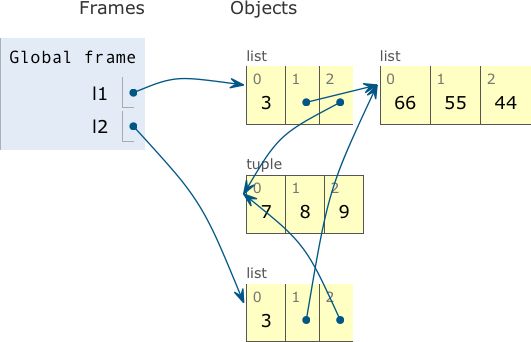
示例 8-6 为一个包含另一个列表的列表做浅复制;把这段代码复制粘贴到 Python Tutor 网站中,看看动画效果
l1 = [3, [66, 55, 44], (7, 8, 9)]
l2 = list(l1)
l1.append(100) # 把 100 追加到 l1 ��中,对 l2 没有影响
l1[1].remove(55) # 把内部列表 l1[1] 中的 55 删除。这对 l2 有影响,因为 l2[1] 绑定的列表与 l1[1] 是同一个
print('l1:', l1)
print('l2:', l2)
l2[1] += [33, 22] # 对可变的对象来说,如 l2[1] 引用的列表,+= 运算符就地修改列表。这次修改在 l1[1] 中也有体现,因为它是 l2[1] 的别名
l2[2] += (10, 11) # 对元组来说,+= 运算符创建一个新元组,然后重新绑定给变量 l2[2]。这等同于 l2[2] = l2[2] + (10, 11)。现在,l1 和 l2 中最后位置上的元组不是同一个对象
print('l1:', l1)
print('l2:', l2)
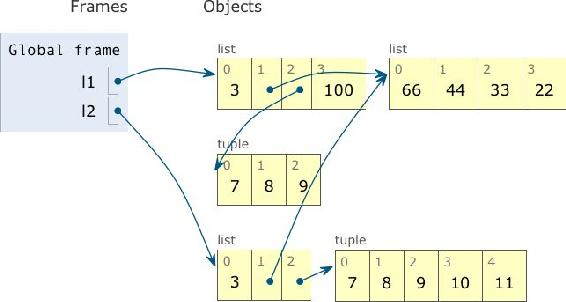
示例 8-7 示例 8-6 的输出
l1: [3, [66, 44], (7, 8, 9), 100]
l2: [3, [66, 44], (7, 8, 9)]
l1: [3, [66, 44, 33, 22], (7, 8, 9), 100]
l2: [3, [66, 44, 33, 22], (7, 8, 9, 10, 11)]
l1 和 l2 的最终状态:二者依然引用同一个列表对象,现在列表的值是 [66, 44, 33, 22],不过 l2[2] += (10, 11) 创建一个新元组,内容是 (7, 8, 9, 10, 11),它与 l1[2] 引用的元组 (7, 8, 9) 无关
浅复制容易操作,但是得到的结果可能并不是你想要的
为任意对象做深复制和浅复制
浅复制没什么问题,�但有时我们需要的是深复制(即副本不共享内部对象的引用)。
copy 模块提供的 deepcopy 和 copy 函数能为任意对象做深复制和浅复制。
注意,一般来说,深复制不是件简单的事。如果对象有循环引用,那么这个朴素的算法会进入无限循环。deepcopy 函数会记住已经复制的对象,因此能优雅地处理循环引用
示例 8-10 循环引用:
b引用a,然后追加到a中;deepcopy会想办法复制a
>>> a = [10, 20]
>>> b = [a, 30]
>>> a.append(b)
>>> a
[10, 20, [[...], 30]]
>>> from copy import deepcopy
>>> c = deepcopy(a)
>>> c
[10, 20, [[...], 30]]
函数的参数作为引用时
Python 唯一支持的参数传递模式是共享传参(call by sharing)。多数面向对象语言都采用这一模式,包括 Ruby、Smalltalk 和 Java(Java 的引用类型是这样,基本类型按值传参)。
共享传参指函数的各个形式参数获得实参中各个引用的副本。也就是说,函数内部的形参是实参的别名
这种方案的结果是,函数可能会修改作为参数传入的可变对象,但是无法修改那些对象的标识��(即不能把一个对象替换成另一个对象)
示例 8-11 函数可能会修改接收到的任何可变对象
>>> def f(a, b):
... a += b
... return a
...
>>> x = 1
>>> y = 2
>>> f(x, y)
3
>>> x, y # 没变
(1, 2)
>>> a = [1, 2]
>>> b = [3, 4]
>>> f(a, b)
[1, 2, 3, 4]
>>> a, b # 变了 因为列表的+=是原地进行的
([1, 2, 3, 4], [3, 4])
>>> t = (10, 20)
>>> u = (30, 40)
>>> f(t, u)
(10, 20, 30, 40)
>>> t, u # 没变 因为元组的+=是新建对象
((10, 20), (30, 40))
不要使用可变类型作为参数的默认值
一个正常的 Bus
class Bus:
def __init__(self, passengers=None):
if passengers is None:
self.passengers = []
else:
self.passengers = list(passengers)
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name)
我们以 Bus 类为基础定义一个新类, HauntedBus,然后修改 __init__ 方法。这一次,passengers 的默认值不是 None,而是 [],这样就不用像之前那样使用 if 判断了。这个“聪明的举动”会让我们陷入麻烦。
示例 8-12 一个简单的类,说明可变默认值的危险
class HauntedBus:
"""备受幽灵乘客折磨的校车"""
def __init__(self, passengers=[]):
self.passengers = passengers # 这个赋值语句把 self.passengers 变成 passengers 的别名,而没有传入 passengers 参数时,后者又是默认列表的别名
def pick(self, name):
self.passengers.append(name) # 在 self.passengers 上调用 .remove() 和 .append() 方法时,修改的其实是默认列表,它是函数对象的一个属性。
def drop(self, name):
self.passengers.remove(name)
HauntedBus 的诡异行为如示例 8-13 所示。
示例 8-13 备受幽灵乘客折磨的校车
>>> bus1 = HauntedBus(['Alice', 'Bill'])
>>> bus1.passengers
['Alice', 'Bill']
>>> bus1.pick('Charlie')
>>> bus1.drop('Alice')
>>> bus1.passengers # 目前为止一切正常
['Bill', 'Charlie']
>>> bus2 = HauntedBus() # 一开始,bus2 是空的,因此把默认的空列表赋值给 self.passengers
>>> bus2.pick('Carrie')
>>> bus2.passengers
['Carrie']
>>> bus3 = HauntedBus() # 寄,现在形参 passengers 的默认值成了['Carrie']
>>> bus3.passengers
['Carrie']
>>> bus3.pick('Dave')
>>> bus2.passengers # 登上 bus3 的 Dave 出现在 bus2 中
['Carrie', 'Dave']
>>> bus2.passengers is bus3.passengers # bus2.passengers 和 bus3.passengers 指代同一个列表
True
>>> bus1.passengers # 但 bus1.passengers 是不同的列表
['Bill', 'Charlie']
问题在于,没有指定初始乘客的 HauntedBus 实例会共享同一个乘客列表
⭐ 出现这个问题的根源是,默认值在定义函数时计算(通常在加载模块时),因此默认值变成了函数对象的属性。因此,如果默认值是可变对象,而且修改了它的值,那么后续的函数调用都会受到影响。
运行示例 8-13 中的代码之后,可以审查 HauntedBus.__init__ 对象,看看它的 __defaults__ 属性中的那些幽灵学生:
>>> dir(HauntedBus.__init__) # doctest: +ELLIPSIS
['__annotations__', '__call__', ..., '__defaults__', ...]
>>> HauntedBus.__init__.__defaults__
(['Carrie', 'Dave'],)
最后,我们可以验证 bus2.passengers 是一个别名,它绑定到 HauntedBus.__init__.__defaults__ 属性的第一个元素上:
>>> HauntedBus.__init__.__defaults__[0] is bus2.passengers
True
可变默认值导致的这个问题说明了为什么通常使用 None 作为接收可变值的参数的默认值
防御可变参数
如果定义的函数接收可变参数,应该谨慎考虑调用方是否期望修改传入的参数。
例如,如果函数接收一个字典,而且在处理的过程中要修改它,那么这个副作用要不要体现到函数外部?具体情况具体分析。这其实需要函数的编写者和调用方达成共识。
在本章最后一个校车示例中,TwilightBus 实例与客户共享乘客列表,这会产生意料之外的结果。在分析实现之前,我们先从客户的角度看看 TwilightBus 类是如何工作的。
示例 8-14 从
TwilightBus下车后,乘客消失了
>>> basketball_team = ['Sue', 'Tina', 'Maya', 'Diana', 'Pat']
>>> bus = TwilightBus(basketball_team)
>>> bus.drop('Tina')
>>> bus.drop('Pat')
>>> basketball_team
['Sue', 'Maya', 'Diana']
TwilightBus 违反了设计接口的最佳实践,即“最少惊讶原则”。学生从校车中下车后,她的名字就从篮球队的名单中消失了,这确实让人惊讶。
示例 8-15 是 TwilightBus 的实现,随后解释了出现这个问题的原因。
示例 8-15 一个简单的类,说明接受可变参数的风险
class TwilightBus:
"""让乘客销声匿迹的校车"""
def __init__(self, passengers=None):
if passengers is None:
self.passengers = [] ➊
else:
self.passengers = passengers # 这个赋值语句把 self.passengers 变成 passengers 的别名,而后者是传给 __init__ 方法的实参的别名
def pick(self, name):
self.passengers.append(name)
def drop(self, name):
self.passengers.remove(name) # 在 self.passengers 上调用 .remove() 和 .append() 方法其实会修改传给构造方法的那个列表
这里的问题是,校车为传给构造方法的列表创建了别名。正确的做法是,校车自己维护乘客列表。
修正的方法很简单:在 __init__ 中,传入 passengers 参数时,应该把参数值的副本赋值给 self.passengers
def __init__(self, passengers=None):
if passengers is None:
self.passengers = []
else:
self.passengers = list(passengers) # 创建 passengers 列表的副本;如果不是列表,就把它转换成列表。
除非这个方法确实想修改通过参数传入的对象,否则在类中直接把参数赋值给实例变量之前一定要三思,因为这样会为参数对象创建别名。如果不确定,那就创建副本。这样客户会少些麻烦。
del 和垃圾回收
del 语句删除名称,而不是对象。del 命令可能会导致对象被当作垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用,或�者无法得到对象时。
重新绑定也可能会导致对象的引用数量归零,导致对象被销毁。
如果两个对象相互引用,当它们的引用只存在二者之间时,垃圾回收程序会判定它们都无法获取,进而把它们都销毁。
有个
__del__特殊方法,但是它不会销毁实例,不应该在代码中调用。即将销毁实例时,Python 解释器会调用__del__方法,给实例最后的机会,释放外部资源。自己编写的代码很少需要实现__del__代码,有些 Python 新手会花时间实现,但却吃力不讨好,因为__del__很难用对
在 CPython 中,垃圾回收使用的主要算法是引用计数。实际上,每个对象都会统计有多少引用指向自己。当引用计数归零时,对象立即就被销毁:CPython 会在对象上调用 __del__ 方法(如果定义了),然后释放分配给对象的内存
CPython2.0 增加了分代垃圾回收算法,用于检测引用循环中涉及的对象组——如果一组对象之间全是相互引用,即使再出色的引用方式也会导致组中的对象不可获取。Python 的其他实现有更复杂的垃圾回收程序,而且不依赖引用计数,这意味着,对象的引用数量为零时可能不会立即调用 __del__ 方法
为了演示对象生命结束时的情形,示例 8-16 使用 weakref.finalize 注册一个回调函数,在销毁对象时调用。
示例 8-16 没有指向对象的引用时,监视对象生命结束时的情形
>>> import weakref
>>> s1 = {1, 2, 3}
>>> s2 = s1
>>> def bye(): # 这个函数一定不能是要销毁的对象的绑定方法,否则会有一个指向对象的引用
... print('Gone with the wind...')
...
>>> ender = weakref.finalize(s1, bye) # 在 s1 引用的对象上注册 bye 回调
>>> ender.alive # 调用 finalize 对象之前,.alive 属性的值为 True
True
>>> del s1
>>> ender.alive # del 不删除对象,而是删除对象的引用
True
>>> s2 = 'spam' # 重新绑定最后一个引用 s2,让 {1, 2, 3} 无法获取。对象被销毁了,调用了 bye 回调,ender.alive 的值变成了 False
Gone with the wind...
>>> ender.alive
False
示例 8-16 的目的是明确指出 del 不会删除对象,但是执行 del 操作后可能会导致对象不可获取,从而被删除
你可能觉得奇怪,为什么示例 8-16 中的 {1, 2, 3} 对象被销毁了?毕竟,我们把 s1 引用传给 finalize 函数了,而为了监控对象和调用回调,必须要有引用。这是因为,finalize 持有 {1, 2, 3} 的弱引用,参见下一节。
弱引用
正是因为有引用,对象才会在内存中存在。当对象的引用数量归零后,垃圾回收程序会把对象销毁。但是,有时需要引用对象,而不让对象存在的时间超过所需时间。这经常用在缓存中。
弱引用不会增加对象的引用数量。引用的目标对象称为所指对象(referent)。因此我们说,弱引用不会妨碍所指对象被当作垃圾回收。
弱引用在缓存应用中很有用,因为我们不想仅因为被缓存引用着而始终保存缓存对象。
示例 8-17 展示了如何使用 weakref.ref 实例获取所指对象。如果对象存在,调用弱引用可以获取对象;否则返回 None。
示例 8-17 弱引用是可调用的对象,返回的是被引用的对象;如果所指对象不存在了,返回
None
>>> import weakref
>>> a_set = {0, 1}
>>> wref = weakref.ref(a_set) # 创建弱引用对象 wref
>>> wref
<weakref at 0x100637598; to 'set' at 0x100636748>
>>> wref() # 调用 wref() 返回的是被引用的对象,{0, 1}。因为这是控制台会话,所以 {0, 1} 会绑定给 _ 变量
{0, 1}
>>> a_set = {2, 3, 4} # a_set 不再指代 {0, 1} 集合,因此集合的引用数量减少了。但是 _ 变量仍然指代它
>>> wref() # 调用 wref() 依旧返回 {0, 1}
{0, 1}
>>> wref() is None # 计算这个表达式时,{0, 1} 存在,因此 wref() 不是 None。但是,随后 _ 绑定到结果值 False。现在 {0, 1} 没有强引用了
False
>>> wref() is None # 因为 {0, 1} 对象不存在了,所以 wref() 返回 None
True
示例 8-17 是一个控制台会话,Python 控制台会自动把 _ 变量绑定到结果不为 None 的表达式结果上。
这对我想演示的行为有影响,不过却凸显了一个实际问题:微观管理内存时,往往会得到意外的结果,因为不明显的隐式赋值会为对象创建新引用。控制台中的 _ 变量是一例。调用跟踪对象也常导致意料之外的引用。
weakref.ref类其实是低层接口,供高级用途使用,多数程序最好使用weakref集合和finalize。也就是说,应该使用WeakKeyDictionary、WeakValueDictionary、WeakSet和finalize(在内部使用弱引用),不要自己动手创建并处理weakref.ref实例。我们在示例 8-17 中那么做是希望借助实际使用weakref.ref来褪去它的神秘色彩。但是实际上,多数时候 Python 程序都使用weakref集合。
WeakValueDictionary 简介
WeakValueDictionary 类实现的是一种可变映射,里面的值是对象的弱引用。
被引用的对象在程序中的其他地方被当作垃圾回收后,对应的键会自动从 WeakValueDictionary 中删除。因此,WeakValueDictionary 经常用于缓存。
示例 8-18
Cheese有个kind属性和标准的字符串表示形式
class Cheese:
def __init__(self, kind):
self.kind = kind
def __repr__(self):
return 'Cheese(%r)' % self.kind
在示例 8-19 中,我们把 catalog 中的各种奶酪载入 WeakValueDictionary 实现的 stock 中。然而,删除 catalog 后,stock 中只剩下一种奶酪了。
示例 8-19 顾客:“你们店里到底有没有奶酪?”
>>> import weakref
>>> stock = weakref.WeakValueDictionary()
>>> catalog = [Cheese('Red Leicester'), Cheese('Tilsit'),
... Cheese('Brie'), Cheese('Parmesan')]
...
>>> for cheese in catalog:
... stock[cheese.kind] = cheese
...
>>> sorted(stock.keys())
['Brie', 'Parmesan', 'Red Leicester', 'Tilsit']
>>> del catalog
>>> sorted(stock.keys())
['Parmesan'] # cheese 实际上还引用着它
>>> del cheese
>>> sorted(stock.keys())
[]
临时变量引用了对象,这可能会导致该变量的存在时间比预期长。通常,这对局部变量来说不是问题,因为它们在函数返回时会被销毁。
但是在示例 8-19 中,for 循环中的变量 cheese 是全局变量,除非显式删除,否则不会消失。
与 WeakValueDictionary 对应的是 WeakKeyDictionary,后者的键是弱引用。它可以为应用中其他部分拥有的对象附加数据,这样就无需为对象添加属性。这对覆盖属性访问权限的对象尤其有用。
weakref 模块还提供了 WeakSet 类,按照文档的说明,这个类的作用很简单:“保存元素弱引用的集合类。元素没有强引用时,集合会把它删除。”如果一个类需要知道所有实例,一种好的方案是创建一个 WeakSet 类型的类属性,保存实例的引用。如果使用常规的 set,实例永远不会被垃圾回收,因为类中有实例的强引用,而类存在的时间与 Python 进程一样长,除非显式删除类。
弱引用的局限
不是每个 Python 对象都可以作为弱引用的目标(或称所指对象)。
基本的 list 和 dict 实例不能作为所指对象,但是它们的子类可以轻松地解决这个问题:
class MyList(list):
"""list的子类,实例可以作为弱引用的目标"""
a_list = MyList(range(10))
# a_list可以作为弱引用的目标
wref_to_a_list = weakref.ref(a_list)
set 实例可以作为所指对象。用户定义的类型也没问题,这就解释了示例 8-19 中为什么使用那个简单的 Cheese 类。
但是,int 和 tuple 实例不能作为弱引用的目标,甚至它们的子类也不行。
这些局限基本上是 CPython 的实现细节,在其他 Python 解释器中情况可能不一样。这些局限是内部优化导致的结果
Python 对不可变类型施加的把戏
对元组 t 来说,t[:] 不创建副本,而是返回同一个对象的引用。此外,tuple(t) 获得的也是同一个元组的引用
文档明确指出了这个行为。在 Python 控制台中输入
help(tuple),你会看到这句话:“如果参数是一个元组,那么返回值是同一个对象。
示例 8-20 使用另一个元组构建元组,得到的其实是同一个元组
>>> t1 = (1, 2, 3)
>>> t2 = tuple(t1)
>>> t2 is t1
True
>>> t3 = t1[:]
>>> t3 is t1
True
str、bytes 和 frozenset 实例也有这种行为。注意,frozenset 实例不是序列,因此不能使用 fs[:](fs 是一个 frozenset 实例)。但是,fs.copy() 具有相同的效果:它会欺骗你,返回同一个对象的引用,而不是创建一个副本(tuple 同理)
copy方法不会复制所有对象,这是一个善意的谎言,为的是接口的兼容性:这使得frozenset的兼容性比set强。两个不可变对象是同一个对象还是副本,反正对最终用户来说没有区别。
示例 8-21 字符串字面量可能会创建共享的对象
>>> t1 = (1, 2, 3)
>>> t3 = (1, 2, 3)
>>> t3 is t1 # t1 和 t3 相等,但不是同一个对象
False
>>> s1 = 'ABC'
>>> s2 = 'ABC'
>>> s2 is s1 # 奇怪的事发生了,a 和 b 指代同一个字符串
True
共享字符串字面量是一种优化措施,称为驻留(interning)。CPython 还会在小的整数上使用这个优化措施,防止重复创建“热门”数字,如 0、-1 和 42。
注意,CPython 不会驻留所有字符串和整数,驻留的条件是实现细节,而且没有文档说明。
千万不要依赖字符串或整数的驻留!比较字符串或整数是否相等时,应该使用
==,而不是is。驻留是 Python 解释器内部使用的一�个特性
本节讨论的把戏,包括 frozenset.copy() 的行为,是“善意的谎言”,能节省内存,提升解释器的速度。别担心,它们不会为你带来任何麻烦,因为只有不可变类型会受到影响。或许这些细枝末节的最佳用途是与其他 Python 程序员打赌,提高自己的胜算
细节
- 其实,对象的类型也可以变,方法只有一种:为
__class__属性指定其他类。但这是在作恶。 - 在“纯”函数式编程中,所有数据都是不可变的,如果为集合追加元素,那么其实会创建新的集合